- Overview
- System requirements
- Supported cloud providers
- Runner configuration
- Limit the number of VMs created by the Docker Machine executor
- Autoscaling algorithm and parameters
- How
concurrent,limitandIdleCountgenerate the upper limit of running machines - The
IdleScaleFactorstrategy - Configure autoscaling periods
- Distributed runners caching
- Distributed container registry mirroring
- A complete example of
config.toml
Docker Machine Executor autoscale configuration
- The autoscale feature was introduced in GitLab Runner 1.1.0.
Autoscale provides the ability to use resources in a more elastic and dynamic way.
GitLab Runner can autoscale, so that your infrastructure contains only as many build instances as are necessary at any time. If you configure GitLab Runner to only use autoscale, the system on which GitLab Runner is installed acts as a bastion for all the machines it creates. This machine is referred to as a “Runner Manager.”
Docker Machine autoscaler creates one container per VM, regardless of the limit and concurrent configuration.
Overview
When this feature is enabled and configured properly, jobs are executed on
machines created on demand. Those machines, after the job is finished, can
wait to run the next jobs or can be removed after the configured IdleTime.
In case of many cloud providers this helps to utilize the cost of already used
instances.
Below, you can see a real life example of the GitLab Runner autoscale feature, tested on GitLab.com for the GitLab Community Edition project:
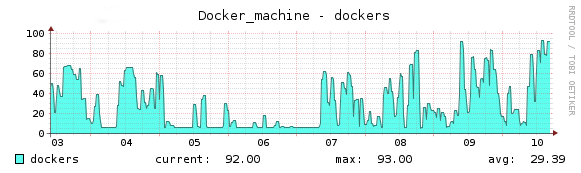
Each machine on the chart is an independent cloud instance, running jobs inside of Docker containers.
System requirements
Before configuring autoscale, you must:
- Prepare your own environment.
- Optionally use a forked version of Docker machine supplied by GitLab, which has some additional fixes.
Supported cloud providers
The autoscale mechanism is based on Docker Machine. All supported virtualization and cloud provider parameters are available at the GitLab-managed fork of Docker Machine.
Runner configuration
This section describes the significant autoscale parameters. For more configurations details read the advanced configuration.
Runner global options
| Parameter | Value | Description |
|---|---|---|
concurrent
| integer | Limits how many jobs globally can be run concurrently. This is the most upper limit of number of jobs using all defined runners, local and autoscale. Together with limit (from [[runners]] section) and IdleCount (from [runners.machine] section) it affects the upper limit of created machines.
|
[[runners]] options
| Parameter | Value | Description |
|---|---|---|
executor
| string | To use the autoscale feature, executor must be set to docker+machine.
|
limit
| integer | Limits how many jobs can be handled concurrently by this specific token. 0 means don’t limit. For autoscale, it’s the upper limit of machines created by this provider (in conjunction with concurrent and IdleCount).
|
[runners.machine] options
Configuration parameters details can be found
in GitLab Runner - Advanced Configuration - The [runners.machine] section.
[runners.cache] options
Configuration parameters details can be found
in GitLab Runner - Advanced Configuration - The [runners.cache] section
Additional configuration information
There is also a special mode, when you set IdleCount = 0. In this mode,
machines are always created on-demand before each job (if there is no
available machine in Idle state). After the job is finished, the autoscaling
algorithm works
the same as it is described below.
The machine is waiting for the next jobs, and if no one is executed, after
the IdleTime period, the machine is removed. If there are no jobs, there
are no machines in Idle state.
If the IdleCount is set to a value greater than 0, then idle VMs are created in the background. The runner acquires an existing idle VM before asking for a new job.
- If the job is assigned to the runner, then that job is sent to the previously acquired VM.
- If the job is not assigned to the runner, then the lock on the idle VM is released and the VM is returned back to the pool.
Limit the number of VMs created by the Docker Machine executor
To limit the number of virtual machines (VMs) created by the Docker Machine executor, use the limit parameter in the [[runners]] section of the config.toml file.
The concurrent parameter does not limit the number of VMs.
As detailed here, one process can be configured to manage multiple runner workers.
This example illustrates the values set in the config.toml file for one runner process:
concurrent = 100
[[runners]]
name = "first"
executor = "shell"
limit = 40
(...)
[[runners]]
name = "second"
executor = "docker+machine"
limit = 30
(...)
[[runners]]
name = "third"
executor = "ssh"
limit = 10
[[runners]]
name = "fourth"
executor = "virtualbox"
limit = 20
(...)
With this configuration:
- One runner process can create four different runner workers using different execution environments.
- The
concurrentvalue is set to 100, so this one runner will execute a maximum of 100 concurrent GitLab CI/CD jobs. - Only the
secondrunner worker is configured to use the Docker Machine executor and therefore can automatically create VMs. - The
limitsetting of30means that thesecondrunner worker can execute a maximum of 30 CI/CD jobs on autoscaled VMs at any point in time. - While
concurrentdefines the global concurrency limit across multiple[[runners]]workers,limitdefines the maximum concurrency for a single[[runners]]worker.
In this example, the runner process handles:
- Across all
[[runners]]workers, up to 100 concurrent jobs. - For the
firstworker, no more than 40 jobs, which are executed with theshellexecutor. - For the
secondworker, no more than 30 jobs, which are executed with thedocker+machineexecutor. Additionally, Runner will maintain VMs based on the autoscaling configuration in[runners.machine], but no more than 30 VMs in all states (idle, in-use, in-creation, in-removal). - For the
thirdworker, no more than 10 jobs, executed with thesshexecutor. - For the
fourthworker, no more than 20 jobs, executed with thevirtualboxexecutor.
In this second example, there are two [[runners]] workers configured to use the docker+machine executor. With this configuration, each runner worker manages a separate pool of VMs that are constrained by the value of the limit parameter.
concurrent = 100
[[runners]]
name = "first"
executor = "docker+machine"
limit = 80
(...)
[[runners]]
name = "second"
executor = "docker+machine"
limit = 50
(...)
In this example:
- The runner processes no more than 100 jobs (the value of
concurrent). - The runner process executes jobs in two
[[runners]]workers, each of which uses thedocker+machineexecutor. - The
firstrunner can create a maximum of 80 VMs. Therefore this runner can execute a maximum of 80 jobs at any point in time. - The
secondrunner can create a maximum of 50 VMs. Therefore this runner can execute a maximum of 50 jobs at any point in time.
130 (80 + 50 = 130), the concurrent value of 100 at the global level means that this runner process can execute a maximum of 100 jobs concurrently.Autoscaling algorithm and parameters
The autoscaling algorithm is based on these parameters:
IdleCountIdleCountMinIdleScaleFactorIdleTimeMaxGrowthRatelimit
We say that each machine that does not run a job is in Idle state. When
GitLab Runner is in autoscale mode, it monitors all machines and ensures that
there is always an IdleCount of machines in Idle state.
IdleScaleFactor and IdleCountMin settings which change this
behavior a little. Refer to the dedicated section for more details.If there is an insufficient number of Idle machines, GitLab Runner
starts provisioning new machines, subject to the MaxGrowthRate limit.
Requests for machines above the MaxGrowthRate value are put on hold
until the number of machines being created falls below MaxGrowthRate.
At the same time, GitLab Runner is checking the duration of the Idle state of
each machine. If the time exceeds the IdleTime value, the machine is
automatically removed.
Example: Let’s suppose, that we have configured GitLab Runner with the following autoscale parameters:
[[runners]]
limit = 10
# (...)
executor = "docker+machine"
[runners.machine]
MaxGrowthRate = 1
IdleCount = 2
IdleTime = 1800
# (...)
At the beginning, when no jobs are queued, GitLab Runner starts two machines
(IdleCount = 2), and sets them in Idle state. Notice that we have also set
IdleTime to 30 minutes (IdleTime = 1800).
Now, let’s assume that 5 jobs are queued in GitLab CI. The first 2 jobs are
sent to the Idle machines of which we have two. GitLab Runner now notices that
the number of Idle is less than IdleCount (0 < 2), so it starts new
machines. These machines are provisioned sequentially, to prevent exceeding the
MaxGrowthRate.
The remaining 3 jobs are assigned to the first machine that is ready. As an optimization, this can be a machine that was busy, but has now completed its job, or it can be a newly provisioned machine. For the sake of this example, let us assume that provisioning is fast, and the provisioning of new machines completed before any of the earlier jobs completed.
We now have 1 Idle machine, so GitLab Runner starts another 1 new machine to
satisfy IdleCount. Because there are no new jobs in queue, those two
machines stay in Idle state and GitLab Runner is satisfied.
This is what happened: We had 2 machines, waiting in Idle state for new jobs. After the 5 jobs where queued, new machines were created, so in total we had 7 machines. Five of them were running jobs, and 2 were in Idle state, waiting for the next jobs.
The algorithm still works the same way; GitLab Runner creates a new
Idle machine for each machine used for the job execution until IdleCount
is satisfied. Those machines are created up to the number defined by
limit parameter. If GitLab Runner notices that there is a limit number of
total created machines, it stops autoscaling, and new jobs must
wait in the job queue until machines start returning to Idle state.
In the above example we always have two idle machines. The IdleTime
applies only when we are over the IdleCount. Then we try to reduce the number
of machines to IdleCount.
Scaling down:
After the job is finished, the machine is set to Idle state and is waiting
for the next jobs to be executed. Let’s suppose that we have no new jobs in
the queue. After the time designated by IdleTime passes, the Idle machines
are removed. In our example, after 30 minutes, all machines are removed
(each machine after 30 minutes from when last job execution ended) and GitLab
Runner starts to keep an IdleCount of Idle machines running, just like
at the beginning of the example.
So, to sum up:
- We start GitLab Runner
- GitLab Runner creates 2 idle machines
- GitLab Runner picks one job
- GitLab Runner creates one more machine to fulfill the strong requirement of always having the two idle machines
- Job finishes, we have 3 idle machines
- When one of the three idle machines goes over
IdleTimefrom the time when last time it picked the job it is removed - GitLab Runner always has at least 2 idle machines waiting for fast picking of the jobs
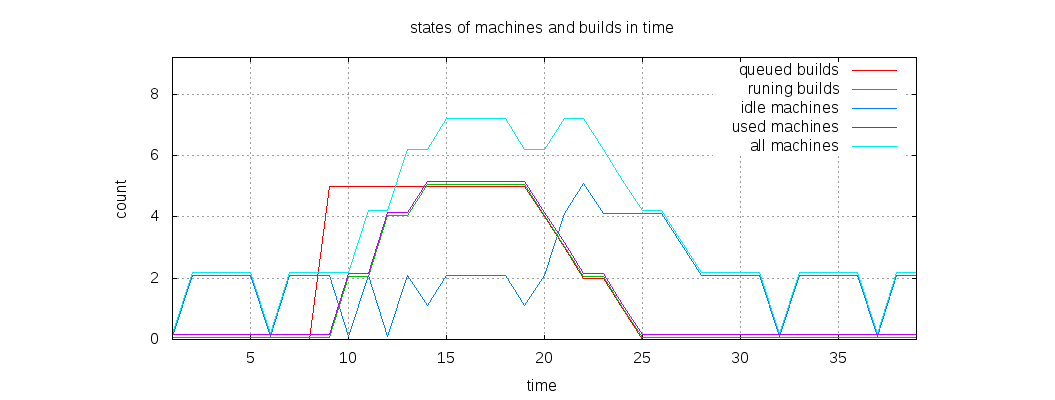
Below you can see a comparison chart of jobs statuses and machines statuses in time:
How concurrent, limit and IdleCount generate the upper limit of running machines
A magic equation doesn’t exist to tell you what to set limit or
concurrent to. Act according to your needs. Having IdleCount of Idle
machines is a speedup feature. You don’t need to wait 10s/20s/30s for the
instance to be created. But as a user, you’d want all your machines (for which
you need to pay) to be running jobs, not stay in Idle state. So you should
have concurrent and limit set to values that run the maximum count of
machines you are willing to pay for. As for IdleCount, it should be set to a
value that generates a minimum amount of not used machines when the job
queue is empty.
Let’s assume the following example:
concurrent=20
[[runners]]
limit = 40
[runners.machine]
IdleCount = 10
In the above scenario the total amount of machines we could have is 30. The
limit of total machines (building and idle) can be 40. We can have 10 idle
machines but the concurrent jobs are 20. So in total we can have 20
concurrent machines running jobs and 10 idle, summing up to 30.
But what happens if the limit is less than the total amount of machines that
could be created? The example below explains that case:
concurrent=20
[[runners]]
limit = 25
[runners.machine]
IdleCount = 10
In this example, you can have a maximum of 20 concurrent jobs and 25 machines.
In the worst case scenario, you can’t have 10 idle machines, but only 5, because the limit is 25.
The IdleScaleFactor strategy
- Introduced as experimental feature in GitLab Runner 14.6.
The IdleCount parameter defines a static number of Idle machines that runner should sustain.
The value you assign depends on your use case.
You can start by assigning a reasonable small number of machines in the Idle state, and have them
automatically adjust to a bigger number, depending on the current usage. To do that, use the experimental
IdleScaleFactor setting.
IdleScaleFactor internally is an float64 value and requires the float format to be used,
for example: 0.0, or 1.0 or ,1.5 etc. If an integer format will be used (for example IdleScaleFactor = 1),
Runner’s process will fail with the error:
FATAL: Service run failed error=toml: cannot load TOML value of type int64 into a Go float.When you use this setting, GitLab Runner tries to sustain a defined number of
machines in the Idle state. However, this number is no longer static. Instead of using IdleCount,
GitLab Runner checks how many machines are currently in use and defines the desired Idle capacity as
a factor of that number.
Of course if there would be no currently used machines, IdleScaleFactor would evaluate to no Idle machines
to maintain. Because of how the autoscaling algorithm works, if IdleCount is greater than 0 (and only then
the IdleScaleFactor is applicable), Runner will not ask for jobs if there are no Idle machines that can handle
them. Without new jobs the number of used machines would not rise, so IdleScaleFactor would constantly evaluate
to 0. And this would block the Runner in unusable state.
Therefore, we’ve introduced the second setting: IdleCountMin. It defines the minimum number of Idle machines
that need to be sustained no matter what IdleScaleFactor will evaluate to. The setting can’t be set to less than
1 if IdleScaleFactor is used. If done so, Runner will automatically set it to 1.
You can also use IdleCountMin to define the minimum number of Idle machines that should always be available.
This allows new jobs entering the queue to start quickly. As with IdleCount, the value you assign
depends on your use case.
For example:
concurrent=200
[[runners]]
limit = 200
[runners.machine]
IdleCount = 100
IdleCountMin = 10
IdleScaleFactor = 1.1
In this case, when Runner approaches the decision point, it checks how many machines are currently in use.
Let’s say we currently have 5 Idle machines and 10 machines in use. Multiplying it by the IdleScaleFactor
Runner decides that it should have 11 Idle machines. So 6 more are created.
If you have 90 Idle machines and 100 machines in use, based on the IdleScaleFactor, GitLab Runner sees that
it should have 100 * 1.1 = 110 Idle machines. So it again starts creating new ones. However, when it reaches
the number of 100 Idle machines, it recognizes that this is the upper limit defined by IdleCount, and no
more Idle machines are created.
If the 100 Idle machines in use goes down to 20, the desired number of Idle machines is 20 * 1.1 = 22,
and GitLab Runner starts slowly terminating the machines. As described above, GitLab Runner will remove the
machines that weren’t used for the IdleTime. Therefore, the removal of too many Idle VMs will not be done
too aggressively.
If the number of Idle machines goes down to 0, the desired number of Idle machines is 0 * 1.1 = 0. This,
however, is less than the defined IdleCountMin setting, so Runner will slowly start removing the Idle VMs
until 10 remain. After that point, scaling down stops and Runner keeps 10 machines in Idle state.
Configure autoscaling periods
Autoscaling can be configured to have different values depending on the time period. Organizations might have regular times when spikes of jobs are being executed, and other times with few to no jobs. For example, most commercial companies work from Monday to Friday in fixed hours, like 10am to 6pm. On nights and weekends for the rest of the week, and on the weekends, no pipelines are started.
These periods can be configured with the help of [[runners.machine.autoscaling]] sections.
Each of them supports setting IdleCount and IdleTime based on a set of Periods.
How autoscaling periods work
In the [runners.machine] settings, you can add multiple [[runners.machine.autoscaling]] sections, each one with its own IdleCount, IdleTime, Periods and Timezone properties. A section should be defined for each configuration, proceeding in order from the most general scenario to the most specific scenario.
All sections are parsed. The last one to match the current time is active. If none match, the values from the root of [runners.machine] are used.
For example:
[runners.machine]
MachineName = "auto-scale-%s"
MachineDriver = "google"
IdleCount = 10
IdleTime = 1800
[[runners.machine.autoscaling]]
Periods = ["* * 9-17 * * mon-fri *"]
IdleCount = 50
IdleTime = 3600
Timezone = "UTC"
[[runners.machine.autoscaling]]
Periods = ["* * * * * sat,sun *"]
IdleCount = 5
IdleTime = 60
Timezone = "UTC"
In this configuration, every weekday between 9 and 16:59 UTC, machines are overprovisioned to handle the large traffic during operating hours. On the weekend, IdleCount drops to 5 to account for the drop in traffic.
The rest of the time, the values are taken from the defaults in the root - IdleCount = 10 and IdleTime = 1800.
You can specify the Timezone of a period, for example "Australia/Sydney". If you don’t,
the system setting of the host machine of every runner is used. This
default can be stated as Timezone = "Local" explicitly.
More information about the syntax of [[runner.machine.autoscaling]] sections can be found
in GitLab Runner - Advanced Configuration - The [runners.machine] section.
Distributed runners caching
To speed up your jobs, GitLab Runner provides a cache mechanism where selected directories and/or files are saved and shared between subsequent jobs.
This is working fine when jobs are run on the same host, but when you start using the GitLab Runner autoscale feature, most of your jobs run on a new (or almost new) host, which executes each job in a new Docker container. In that case, you can’t take advantage of the cache feature.
To overcome this issue, together with the autoscale feature, the distributed runners cache feature was introduced.
This feature uses configured object storage server to share the cache between used Docker hosts. GitLab Runner queries the server and downloads the archive to restore the cache, or uploads it to archive the cache.
To enable distributed caching, you have to define it in config.toml using the
[runners.cache] directive:
[[runners]]
limit = 10
executor = "docker+machine"
[runners.cache]
Type = "s3"
Path = "path/to/prefix"
Shared = false
[runners.cache.s3]
ServerAddress = "s3.example.com"
AccessKey = "access-key"
SecretKey = "secret-key"
BucketName = "runner"
Insecure = false
In the example above, the S3 URLs follow the structure
http(s)://<ServerAddress>/<BucketName>/<Path>/runner/<runner-id>/project/<id>/<cache-key>.
To share the cache between two or more runners, set the Shared flag to true.
This flag removes the runner token from the URL (runner/<runner-id>) and
all configured runners share the same cache. You can also
set Path to separate caches between runners when cache sharing is enabled.
Distributed container registry mirroring
To speed up jobs executed inside of Docker containers, you can use the Docker registry mirroring service. This service provides a proxy between your Docker machines and all used registries. Images are downloaded one time by the registry mirror. On each new host, or on an existing host where the image is not available, the image is downloaded from the configured registry mirror.
Provided that the mirror exists in your Docker machines LAN, the image downloading step should be much faster on each host.
To configure the Docker registry mirroring, you have to add MachineOptions to
the configuration in config.toml:
[[runners]]
limit = 10
executor = "docker+machine"
[runners.machine]
(...)
MachineOptions = [
(...)
"engine-registry-mirror=http://10.11.12.13:12345"
]
Where 10.11.12.13:12345 is the IP address and port where your registry mirror
is listening for connections from the Docker service. It must be accessible for
each host created by Docker Machine.
Read more about how to use a proxy for containers.
A complete example of config.toml
The config.toml below uses the google Docker Machine driver:
concurrent = 50 # All registered runners can run up to 50 concurrent jobs
[[runners]]
url = "https://gitlab.com"
token = "RUNNER_TOKEN" # Note this is different from the registration token used by `gitlab-runner register`
name = "autoscale-runner"
executor = "docker+machine" # This runner is using the 'docker+machine' executor
limit = 10 # This runner can execute up to 10 jobs (created machines)
[runners.docker]
image = "ruby:2.7" # The default image used for jobs is 'ruby:2.7'
[runners.machine]
IdleCount = 5 # There must be 5 machines in Idle state - when Off Peak time mode is off
IdleTime = 600 # Each machine can be in Idle state up to 600 seconds (after this it will be removed) - when Off Peak time mode is off
MaxBuilds = 100 # Each machine can handle up to 100 jobs in a row (after this it will be removed)
MachineName = "auto-scale-%s" # Each machine will have a unique name ('%s' is required)
MachineDriver = "google" # Refer to Docker Machine docs on how to authenticate: https://docs.docker.com/machine/drivers/gce/#credentials
MachineOptions = [
"google-project=GOOGLE-PROJECT-ID",
"google-zone=GOOGLE-ZONE", # e.g. 'us-central-1'
"google-machine-type=GOOGLE-MACHINE-TYPE", # e.g. 'n1-standard-8'
"google-machine-image=ubuntu-os-cloud/global/images/family/ubuntu-1804-lts",
"google-username=root",
"google-use-internal-ip",
"engine-registry-mirror=https://mirror.gcr.io"
]
[[runners.machine.autoscaling]] # Define periods with different settings
Periods = ["* * 9-17 * * mon-fri *"] # Every workday between 9 and 17 UTC
IdleCount = 50
IdleCountMin = 5
IdleScaleFactor = 1.5 # Means that current number of Idle machines will be 1.5*in-use machines,
# no more than 50 (the value of IdleCount) and no less than 5 (the value of IdleCountMin)
IdleTime = 3600
Timezone = "UTC"
[[runners.machine.autoscaling]]
Periods = ["* * * * * sat,sun *"] # During the weekends
IdleCount = 5
IdleTime = 60
Timezone = "UTC"
[runners.cache]
Type = "s3"
[runners.cache.s3]
ServerAddress = "s3.eu-west-1.amazonaws.com"
AccessKey = "AMAZON_S3_ACCESS_KEY"
SecretKey = "AMAZON_S3_SECRET_KEY"
BucketName = "runner"
Insecure = false
Note that the MachineOptions parameter contains options for the google
driver which is used by Docker Machine to spawn machines hosted on Google Compute Engine,
and one option for Docker Machine itself (engine-registry-mirror).